Parallelizing Earth Engine feature collections with Dask
Dask is a Python package that allows you to easily parallelize data analysis, whether you’re working with arrays, dataframes, or pretty much any other data format. With a little effort, we can get it to work with an Earth Engine feature collection, allowing us to convert from cloud-based vector data to a client-side geodataframe with parallel requests and lazy evaluation.
A Quick Intro to Dask Dataframes
A Dask dataframe works a lot like a Pandas dataframe with a few notable benefits:
- Your data is automatically split into chunks, where each chunk is a Pandas dataframe. This allows Dask to 1) process large datasets that can’t fit completely into memory, and 2) parallelize operations across chunks.
- Dask can take advantage of lazy evaluation. Load a dataset, filter it, group it, aggregate a summary statistic - nothing is actually run until you call
compute. At that point, Dask will figure out the most efficient way to run all of the operations you’ve chained together, optimizing for memory usage and performance. Depending on the data format, it may be able to avoid ever reading portions of the data you don’t need.
With those benefits in mind, let’s see how we can use Dask to parallelize the download and processing of an Earth Engine feature collection.
Turning a FeatureCollection into a Dask Dataframe
If your data is stored in a file, you can load it just like Pandas with dd.read_csv, dd.read_parquet, etc. For an ee.FeatureCollection, we’ll need to build our own data loading pipeline. A Dask dataframe is built from a series of dataframe chunks, so we’ll need to come up with a way to:
- Split our feature collection into chunks.
- Load each chunk into a dataframe.
- Combine the dataframes into a single Dask dataframe.
Getting the Chunks
For this demo, we’ll use the Global Powerplant Database, which contains the location and metadata for ~29k power plants. We’ll write a function to split that collection into a list of smaller collections that will become our chunks.
fc = ee.FeatureCollection("WRI/GPPD/power_plants")
def get_chunks(fc: ee.FeatureCollection, chunk_size: int=5_000) -> list[ee.FeatureCollection]:
"""
Split a FeatureCollection into a list of smaller FeatureCollection chunks.
"""
n = fc.size().getInfo()
return [ee.FeatureCollection(fc.toList(chunk_size, i)) for i in range(0, n, chunk_size)]
chunks = get_chunks(fc, chunk_size=2_500)
len(chunks)
> 12
We now have a list of 12 FeatureCollection chunks with 2,500 features each. There’s a tradeoff between using smaller chunks that can be distributed across more workers, and using fewer chunks that minimize network request and task graph overhead, so optimizing the chunk size may take some experimentation.
Note: Using toList is computationally expensive, but experimentally I found this approach was faster than the recommended alternative of slicing and filtering based on feature indices.
Loading a Chunk
Next, we’ll need a function to take a single ee.FeatureCollection chunk and return a (geo)dataframe.
import geopandas as gpd
def fc_to_df(fc: ee.FeatureCollection, crs: str="EPSG:4326") -> gpd.GeoDataFrame:
"""
Convert a server-side feature collection to a client-side dataframe.
"""
ee.Initialize()
features = fc.getInfo().get("features", [])
return gpd.GeoDataFrame.from_features(features, crs=crs)
Note that you must run ee.Initialize within the loading function, even if your Python session is already initialized. When Dask parallelizes the loading function, each worker must be initialized independently.
You can test the function by grabbing the first chunk and converting it to a dataframe:
fc_to_df(chunks[0]).shape
> (2500, 23)
Putting it All Together
We’ve got a function to split our feature collection into chunks and a function to load each chunk into a dataframe. The final piece of the puzzle is dask.dataframe.from_map. This will apply our loading function to each chunk, handling the complexity of parallelization and lazy-loading behind the scenes.
import dask.dataframe as dd
df = dd.from_map(fc_to_df, chunks)
df
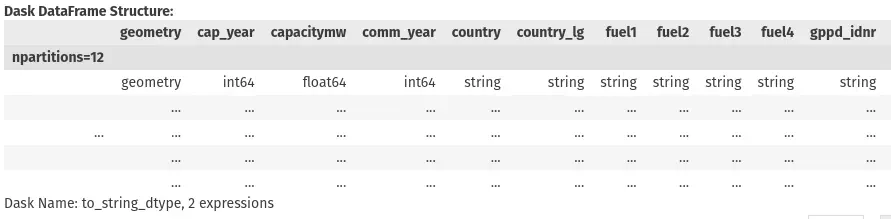
Now we have a Dask dataframe that shows the structure of our feature collection - the columns and datatypes - but no actual data has been loaded yet. We can filter, group, and aggregate the data just like a Pandas dataframe, and when we call compute, Dask will grab each chunk in parallel, run our operations, and spit out the result.
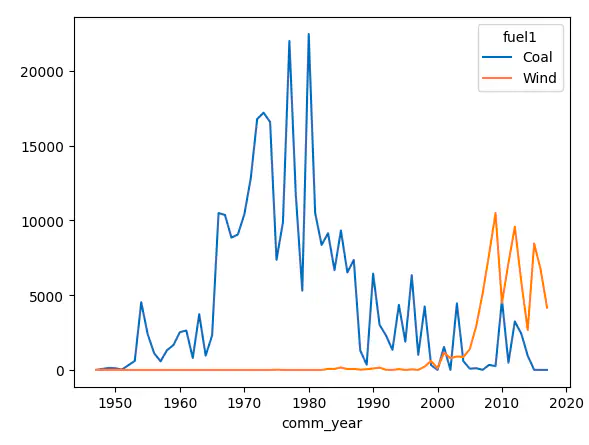
To demonstrate, let’s calculate and plot the total capacity of coal and wind plants in the United States, by year of commissioning:
(
df[df.comm_year.gt(1940) & df.country.eq("USA") & df.fuel1.isin(["Coal", "Wind"])]
.astype({"comm_year": int})
.drop(columns=["geometry"])
.groupby(["comm_year", "fuel1"])
.agg({"capacitymw": "sum"})
.reset_index()
.sort_values(by=["comm_year"])
.compute(scheduler="threads")
.pivot_table(index="comm_year", columns="fuel1", values="capacitymw", fill_value=0)
.plot()
)
Optimization
We’ve got a parallelized, lazy-loading pipeline for Earth Engine feature collections, but let’s see if we can shave off a little time.
Server-side Filtering
Even with parallelization, you’re generally better off doing as much filtering and processing as possible before pulling any data from Earth Engine. In the demo above, filtering by year, country, and fuel type would give an easy performance boost.
Specifying Metadata
When we ran from_map with our chunks, you may have noticed that it took a second to run, even though the data wasn’t loaded until we ran compute. That’s because Dask needs to know the columns and datatypes when the dataframe is created. We didn’t provide them, so Dask eagerly downloaded the first chunk and inferred the metadata from that.
To avoid that eager execution, we can provide the metadata ourselves. We’ll still need to grab some data from Earth Engine, but grabbing a few properties will be faster than an entire chunk. We can use the following function to get metadata for a FeatureCollection:
def get_meta(fc: ee.FeatureCollection) -> pd.DataFrame:
DTYPE_CROSSWALK = {
"String": str,
"Boolean": bool,
"Float": float,
"Integer": int,
"Long": int,
}
cols = fc.limit(0).getInfo()['columns']
cols.pop("system:index")
cols = {k: DTYPE_CROSSWALK.get(v, object) for k, v in cols.items()}
cols = {"geometry": "object", **cols}
return pd.DataFrame(columns=cols.keys()).astype(cols)
Running get_meta will grab the properties from the collection and return a dataframe with the correct columns and datatypes. Passing that meta to from_map will allow Dask to build a dataframe without downloading a single feature:
meta = get_meta(fc)
df = dd.from_map(fc_to_df, chunks, meta=meta)
Column Projection
Column projection is another Dask optimization strategy that allows you to load only the columns that you actually access. We can easily enable column projection by adding a columns argument to our fc_to_df loading function and using it to subset properties before requesting the data from Earth Engine:
def fc_to_df(fc: ee.FeatureCollection, crs: str="EPSG:4326", columns: list[str]=None) -> gpd.GeoDataFrame:
"""
Convert a server-side feature collection to a client-side dataframe (with column projection).
"""
ee.Initialize()
if columns:
fc = fc.select(columns)
features = fc.getInfo().get("features", [])
return gpd.GeoDataFrame.from_features(features, crs=crs)
This technique can be a big performance boost for some data protocols, but with this dataset I found that the overhead of subsetting columns made data transfer about 3x slower. There may be a break-even point with larger collections and more properties, but it should be used with caution.
Conclusion
With a little setup, Dask makes it easy and fast to move a server-side feature collection into a client-side dataframe, with the full benefit of parallelization and lazy evaluation.